Neuroscience inspired principles for Artificial Intelligence
Learning in a living organism always takes place on the background of existing memories. Acquisition of new memories while preserving already existing information imposes two antagonistic requirements: for the plasticity for new learning but – at the same time – for stability to ensure persistence of the old memory. The long-term goal of this proposal is to understand how the stability vs. plasticity dilemma is resolved by neuronal systems and to apply these principles to the artificial systems to enable continuous learning without catastrophic forgetting.
Projects:
Solving the exploitation vs exploration dilemma of reinforcement learning using a network of spiking neurons with reward-modulated STDP
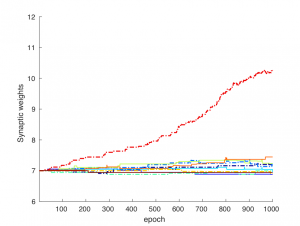 One of the fundamental problems in reinforcement learning (RL) is the exploitation vs exploration dilemma. This dilemma can be observed in the multi-armed bandit task, a classic RL problem. Through continuous interaction with the environment, the agent has to learn a strategy to choose an optimal arm that maximizes the total expected reward. In this study, we considered a multilayer network model of spiking neurons that was capable of learning the unknown parameters of the Bernoulli bandits’ reward distributions. Using reward-modulated spike timing-dependent plasticity (STDP) along with homeostatic mechanisms, the network was capable of learning the unknown information on a synaptic level and ultimately able to identify the arm with the highest reward. In this model, a switch from the mainly exploration phase to the mainly exploitation phase occurred when enough information about each arm had been gained. This phase switch was mediated by the homeostatic plasticity rules that operate to maintain a constant firing rate in the network by reducing synaptic weights to suboptimal arms. In addition, when reward distributions were allowed to vary throughout simulation, the intrinsic randomness of spiking neurons helped to increase performance by forcing the agent to explore the continually changing environment.
One of the fundamental problems in reinforcement learning (RL) is the exploitation vs exploration dilemma. This dilemma can be observed in the multi-armed bandit task, a classic RL problem. Through continuous interaction with the environment, the agent has to learn a strategy to choose an optimal arm that maximizes the total expected reward. In this study, we considered a multilayer network model of spiking neurons that was capable of learning the unknown parameters of the Bernoulli bandits’ reward distributions. Using reward-modulated spike timing-dependent plasticity (STDP) along with homeostatic mechanisms, the network was capable of learning the unknown information on a synaptic level and ultimately able to identify the arm with the highest reward. In this model, a switch from the mainly exploration phase to the mainly exploitation phase occurred when enough information about each arm had been gained. This phase switch was mediated by the homeostatic plasticity rules that operate to maintain a constant firing rate in the network by reducing synaptic weights to suboptimal arms. In addition, when reward distributions were allowed to vary throughout simulation, the intrinsic randomness of spiking neurons helped to increase performance by forcing the agent to explore the continually changing environment.
Simulated sleep helps to generalize knowledge in a spiking network trained with spike-timing dependent plasticity (STDP)
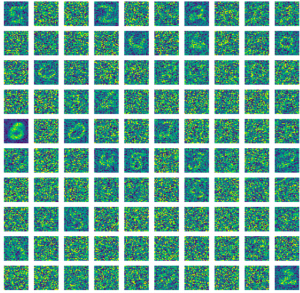 The current state of artificial neural networks suffers from a generalization problem – they excel at representing data seen so far at the expense of representing data not explicitly learned. This problem results in the need for expansive training sets that capture the variability in the task at hand which may not always exist. In the mammalian brain, evidence suggests that sleep promotes generalization of learned examples. Replay during sleep of different versions of learned information may enable the brain to form a much more generalized representation of the data. To address the validity of this hypothesis, we utilized a spiking neural network trained with spike-timing dependent plasticity (STDP) previously proposed to perform digit classification on the MNIST dataset. While this network can learn the task, it only reaches high levels of performance (>90%) after training on more than 100,000 images. We took a partially trained network (between 20 and 80% of the full training image set) and applied a sleep-like phase after the learning phase. During the simulated sleep, we modified the intrinsic and synaptic currents to mimic changes in neuromodulator levels, while presenting noisy Poisson input based on the statistics of the MNIST input. We observed an improvement in performance after sleep compared to baseline (before sleep) across different levels of baseline training. This result was most pronounced for the lower levels of baseline training (<50% of full training set) where performance increased from a mean of ~40% to ~55% after sleep. We also found that sleep increased the network’s ability to classify digits with various types of noise compared to before sleep, indicating an ability to generalize beyond the training set.
The current state of artificial neural networks suffers from a generalization problem – they excel at representing data seen so far at the expense of representing data not explicitly learned. This problem results in the need for expansive training sets that capture the variability in the task at hand which may not always exist. In the mammalian brain, evidence suggests that sleep promotes generalization of learned examples. Replay during sleep of different versions of learned information may enable the brain to form a much more generalized representation of the data. To address the validity of this hypothesis, we utilized a spiking neural network trained with spike-timing dependent plasticity (STDP) previously proposed to perform digit classification on the MNIST dataset. While this network can learn the task, it only reaches high levels of performance (>90%) after training on more than 100,000 images. We took a partially trained network (between 20 and 80% of the full training image set) and applied a sleep-like phase after the learning phase. During the simulated sleep, we modified the intrinsic and synaptic currents to mimic changes in neuromodulator levels, while presenting noisy Poisson input based on the statistics of the MNIST input. We observed an improvement in performance after sleep compared to baseline (before sleep) across different levels of baseline training. This result was most pronounced for the lower levels of baseline training (<50% of full training set) where performance increased from a mean of ~40% to ~55% after sleep. We also found that sleep increased the network’s ability to classify digits with various types of noise compared to before sleep, indicating an ability to generalize beyond the training set.
Multimodal Deep Learning
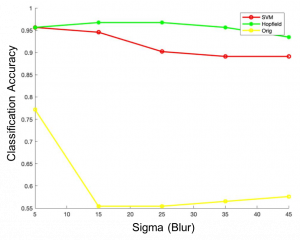 Current deep learning networks (DLNs) are designed to optimally solve unimodal tasks for a particular input modality (e.g., convolutional neural networks (CNNs) for image recognition), but unable to solve tasks that require combining different features from multiple modalities (e.g., visual, semantic, auditory) into one coherent representation. In comparison, biological systems are excellent in their ability to form unique and coherent representations (as is done in the associative cortex) by combining highly variable features from different specialized cortical networks (e.g., primary visual or auditory cortices). This natural strategy has many advantages including superior discrimination performance, stability against adversarial attacks and better scalability. Indeed, if a classification decision is made based on a combination of features from different sensory modalities, noisy or missing information in one modality, can be compensated by another to make a correct decision. Furthermore, different types of sensory information can complement each other by being available at different times within a processing window. We developed a system to process visual input based on separation of background and foreground components. At the first step background and foreground components of the input are processed independently to extract features specific to each component. At the second step, features extracted at the first step are combined and processed by the neural network to improve classification of the image as a whole. Our results show that proposed approach is robust to naturally occurring image perturbations that humans can perceive – such as blur. Conventional CNN using the whole image failed to classify image for any level of blur above Sigma=15
Current deep learning networks (DLNs) are designed to optimally solve unimodal tasks for a particular input modality (e.g., convolutional neural networks (CNNs) for image recognition), but unable to solve tasks that require combining different features from multiple modalities (e.g., visual, semantic, auditory) into one coherent representation. In comparison, biological systems are excellent in their ability to form unique and coherent representations (as is done in the associative cortex) by combining highly variable features from different specialized cortical networks (e.g., primary visual or auditory cortices). This natural strategy has many advantages including superior discrimination performance, stability against adversarial attacks and better scalability. Indeed, if a classification decision is made based on a combination of features from different sensory modalities, noisy or missing information in one modality, can be compensated by another to make a correct decision. Furthermore, different types of sensory information can complement each other by being available at different times within a processing window. We developed a system to process visual input based on separation of background and foreground components. At the first step background and foreground components of the input are processed independently to extract features specific to each component. At the second step, features extracted at the first step are combined and processed by the neural network to improve classification of the image as a whole. Our results show that proposed approach is robust to naturally occurring image perturbations that humans can perceive – such as blur. Conventional CNN using the whole image failed to classify image for any level of blur above Sigma=15
The role of heterosynaptic plasticity in achieving stable yet adaptable memory storage
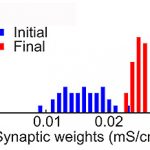 Learning in a living organism always takes place on the background of existing memories. Acquisition of new memories while preserving already existing information imposes two antagonistic requirements: for the plasticity for new learning but – at the same time – for stability to ensure persistence of the old memory. The long-term goal of this proposal is to understand how the stability vs. plasticity dilemma is resolved at the level of a single neuron.
Learning in a living organism always takes place on the background of existing memories. Acquisition of new memories while preserving already existing information imposes two antagonistic requirements: for the plasticity for new learning but – at the same time – for stability to ensure persistence of the old memory. The long-term goal of this proposal is to understand how the stability vs. plasticity dilemma is resolved at the level of a single neuron.
Plasticity may occur at synapses which were directly involved in the activity that caused plastic changes – homosynaptic plasticity, but also at those not active during the induction – heterosynaptic plasticity. Potential targets of heterosynaptic plasticity are much more numerous since only a fraction of the neurons’ input is active at a given time. The direction and the magnitude of these heterosynaptic changes depends on the state of the synapse: synapses with initially low release probability are usually potentiated, while synapses with initially high release probability are typically depressed or did not change. We explore the synapse-type specific predispositions for heterosynaptic plasticity that enable neocortical neurons to combine the ability for both plasticity and persistent information storage.
Problem solving using rewarded STDP
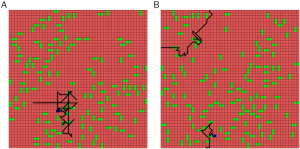 Rewarded spike timing dependent plasticity (STDP) has been implicated as a possible learning mechanism in a variety of brain systems. This mechanism combines unsupervised STDP that modifies synaptic strength depending on the relative timing of presynaptic input and postsynaptic spikes together with a reinforcement signal that modulates synaptic changes. The goal of this project is to combine realistic network structure, spiking neuron models and rewarded STDP to achieve efficient learning and decision making. The long-term goal of this research is apply biologically inspired neural networks to the problems of robotics and automation.
Rewarded spike timing dependent plasticity (STDP) has been implicated as a possible learning mechanism in a variety of brain systems. This mechanism combines unsupervised STDP that modifies synaptic strength depending on the relative timing of presynaptic input and postsynaptic spikes together with a reinforcement signal that modulates synaptic changes. The goal of this project is to combine realistic network structure, spiking neuron models and rewarded STDP to achieve efficient learning and decision making. The long-term goal of this research is apply biologically inspired neural networks to the problems of robotics and automation.
Additional animations accompanying paper “Multi-layer Network Utilizing Rewarded Spike Time Dependent Plasticity to Learn a Foraging Task”, to appear in PLoS Comput Biol, 2017.
| Untrained network | Trained network | |
|---|---|---|
| Untrained network shows random behaviour. |
Trained network shows approaching behaviour towards horizontal bars and aversive to vertical bars. |